- オンラインコースと教材
- AIに関連する書籍
- 7.1 機械学習
- 7.1.1 “Pattern Recognition and Machine Learning” by Christopher M. Bishop
- 7.1.2 “Introduction to Machine Learning with Python: A Guide for Data Scientists” by Andreas C. Müller & Sarah Guido
- 7.2 ディープラーニング
- 7.2.1 “Deep Learning” by Yoshua Bengio, Ian Goodfellow, and Aaron Courville
- 7.2.2 “Hands-On Machine Learning with Scikit-Learn, Keras, and TensorFlow” by Aurélien Géron
- 7.3 AIの倫理と社会的影響
- 7.3.1 “Weapons of Math Destruction: How Big Data Increases Inequality and Threatens Democracy” by Cathy O’Neil
- 7.3.2 “AI Superpowers: China, Silicon Valley, and the New World Order” by Kai-Fu Lee
- 7.4 AIの実践とアプリケーション
- 7.4.1 “Python Machine Learning” by Sebastian Raschka and Vahid Mirjalili
- 7.4.2 “Deep Learning for Computer Vision” by Rajalingappaa Shanmugamani
- 7.5 AIの個別分野
- コミュニティとフォーラム
はじめに
AIが日常生活でどのように使われているか

AI(人工知能)は、我々の日常生活に革命をもたらしています。以下は、AIが日常生活でどのように具体的に活用されているかの一部です。
1.1 スマートフォンの音声アシスタント
スマートフォンの音声アシスタント、例えば「Siri」(Apple)や「Googleアシスタント」(Google)などは、AI技術を活用しています。これらのアシスタントは、音声コマンドを受け付け、質問に答えたり、タスクを実行したりするのにAIの力を借りています。例えば、「明日の天気を教えて」と尋ねると、AIは天気情報を提供します。
1.2 ソーシャルメディアとコンテンツ推薦
ソーシャルメディアプラットフォームやストリーミングサービス(例: Netflix、YouTube)は、AIを使用してユーザーに最適なコンテンツを提供します。あなたが過去の閲覧履歴や評価をもとに、興味を引く可能性の高いコンテンツを推薦しているのはAIです。これにより、ユーザーエクスペリエンスが向上し、新しい興味を発見しやすくなります。
1.3 自動運転技術
自動運転車は、AIとセンサーテクノロジーの組み合わせを使用しています。AIは、周囲の状況を分析し、車両を安全に運転するために必要な決定を行います。例えば、障害物を検知して自動的にブレーキをかけることができます。
1.4 言語翻訳
言語翻訳アプリやサービスは、AIを使用してさまざまな言語間でのコミュニケーションを助けています。例えば、スマートフォンの翻訳アプリは、外国での旅行時にリアルタイムで他言語への翻訳を提供します。
これらはAIが日常生活に与える影響のほんの一部です。AIは私たちの生活をより便利にし、新たな可能性を開拓しています。AI技術の進化により、これからも多くの新しい利用方法が登場することが期待されています。
AIの基本的な定義
AI(人工知能)は、コンピューターシステムが人間の知識と推論能力を模倣し、タスクを実行するために使用する技術です。AIは、以下の要素から成り立っています。
1.1 データ処理と学習
AIは、大量のデータを収集し、それを分析してパターンやトレンドを特定する能力を持っています。このデータ処理の過程において、AIは新しい情報を学び、過去のデータから学んだ知識を活用します。具体的な例として、以下を挙げます:
- スパムフィルター: メールプロバイダは、受信トレイにスパムメールを配信しないようにAIを使用しています。AIは、過去のスパムメールの特徴を学習し、新しいメールをスパムとして分類する能力を持っています。
1.2 自己学習と適応性
AIは時間とともに改善し、自己学習する能力があります。これは、新しいデータをもとにアルゴリズムやモデルを調整し、より正確な予測や意思決定を行うことを意味します。例えば:
- 音声認識: 音声認識ソフトウェアは、ユーザーの発音の変化や新しい言葉を学習し、認識精度を向上させます。これにより、ユーザーの声に合わせた個別の認識が可能となります。
1.3 意思決定能力
AIは与えられた情報に基づいて意思決定を行う能力を持ちます。これは、ルールベースのシステムから機械学習とディープラーニングに基づくシステムまでさまざまな形態を取ります。例えば:
- 株式取引: AIは市場データ、ニュース、過去の取引履歴などを分析し、最適な株式取引のタイミングを決定します。これにより、高度な金融予測が可能となります。
AIの基本的な定義は、これらの要素から成り立っており、コンピューターシステムに知識と推論能力を持たせ、タスクの自動化や問題解決を行うために使用されています。 AIはその応用範囲が広く、私たちの生活の様々な側面に影響を与えています。
AIの歴史
AIの起源と発展
AI(人工知能)の歴史は長く、その発展は多くのマイルストーンを持っています。以下では、AIの起源と主要な発展段階について説明します。
2.1 AIの起源(1950年代)
AIの概念は、1950年代に現れました。その当時、コンピューターサイエンティストたちは、コンピューターに人間の知識と推論能力を持たせることを目指していました。以下は、AIの初期の成果と研究分野です。
- チューリングテスト(Turing Test): イギリスの数学者アラン・チューリングは、コンピューターが人間の会話を模倣することができるかどうかを検討した。これがAIにおける会話ボットの始まりでした。
- 専門家システム: 1950年代から1960年代にかけて、AIの研究者たちは専門家システムの開発に注力しました。これらは特定のドメインで人間の専門知識を模倣し、診断や意思決定を行うためのシステムでした。
2.2 AIの停滞期(1970年代 – 1980年代)
1970年代から1980年代にかけて、AI研究は停滞期に入りました。これは、初期の期待が高すぎたため、AIの限界に直面した結果でした。コンピューターハードウェアとアルゴリズムの不足、計算能力の制約が進展を制限しました。
2.3 エキスパートシステムの成功(1980年代)
1980年代には、エキスパートシステムがAIの成功例として浮上しました。これらのシステムは医療診断、金融アドバイス、エンジニアリングなどの分野で利用され、専門家の知識を活用して問題を解決しました。
2.4 ニューラルネットワークの復活(1990年代 – 2000年代)
1990年代から2000年代にかけて、ニューラルネットワークと呼ばれるAIモデルが再び注目を浴びました。これは、多層の人工ニューロンから成るモデルで、ディープラーニングの基盤となりました。
2.5 ディープラーニングとAIの黄金時代(2010年代以降)
2010年代以降、ディープラーニングに基づくAIが急速に進化し、画像認識、自然言語処理、音声認識などのタスクで驚異的な成果を収めました。GoogleのAlphaGoが囲碁の世界チャンピオンを打ち破るなど、AIの実用性と影響力が拡大しました。
以上がAIの歴史の要点です。AIは進化を続け、将来的にはさらなる革新が期待されています。
AIのマイルストーン
AI(人工知能)の歴史は、いくつかの重要なマイルストーンで特徴づけられています。以下は、AIの発展における主要なマイルストーンです。
2.1 マッカーシーによるダートマス会議(1956年)
- 年: 1956年
- 詳細: ジョン・マッカーシーらが主導したダートマス会議は、AIの誕生の瞬間と言えます。会議で「人工知能(Artificial Intelligence)」という用語が初めて提唱され、AI研究の方向性が示されました。
2.2 チューリングテスト(1950年代)
- 年: 1950年代
- 詳細: アラン・チューリングによって提案されたチューリングテストは、AIが人間のように振る舞うかどうかを判断する基準として重要でした。AIがこのテストに合格することが、人工知能の目標の一つでした。
2.3 エキスパートシステム(1960年代 – 1970年代)
- 年: 1960年代 – 1970年代
- 詳細: エキスパートシステムは、特定の専門家の知識を模倣し、診断や意思決定を行うためのシステムでした。Dendral(化学の専門家システム)やMYCIN(医療診断システム)がその代表例です。
2.4 ニューラルネットワークの再評価(1980年代)
- 年: 1980年代
- 詳細: ニューラルネットワークは1950年代から存在しましたが、1980年代に再評価されました。特にバックプロパゲーションアルゴリズムの改良により、ディープラーニングの基盤となりました。
2.5 IBMのDeep Blueによるチェスでの勝利(1997年)
- 年: 1997年
- 詳細: IBMのDeep Blueは、世界チェスチャンピオンであるカスパロフに対して勝利した初のコンピュータープログラムとして有名です。これはAIが複雑な戦略ゲームで人間に対抗できることを示す重要な瞬間でした。
2.6 Siriの登場(2011年)
- 年: 2011年
- 詳細: AppleのSiriは、スマートフォンの音声アシスタントとして登場し、自然な言語での対話を可能にしました。これはAIの応用が一般的な消費者向けデバイスに拡大した例です。
2.7 AlphaGoの勝利(2016年)
- 年: 2016年
- 詳細: DeepMindのAlphaGoは、囲碁の世界チャンピオンであるリー・セドルに対して勝利しました。これはAIが複雑なゲームにおいても人間を超える能力を持つことを示し、AIの可能性を示唆しました。
これらのマイルストーンは、AIの歴史における重要な瞬間であり、AIの進化と普及に大きな影響を与えました。AIの成果は、技術の進歩と熱心な研究者の努力によって築かれています。
機械学習とディープラーニング

機械学習の基本原則
機械学習は、コンピュータープログラムがデータから学習し、タスクを実行する能力を持たせるための技術です。以下は、機械学習の基本原則です。
3.1.1 データ駆動
機械学習はデータ駆動のアプローチです。アルゴリズムは大量のデータからパターンやトレンドを抽出し、問題を解決するためのモデルを構築します。具体的なデータセットからの学習によって、モデルは問題に適応します。
3.1.2 フィーチャー抽出
機械学習では、データから有用な情報(フィーチャーまたは特徴と呼ばれます)を抽出する必要があります。フィーチャーは、問題の本質的な側面をキャプチャし、モデルが学習しやすい形式に変換します。例えば、写真から顔を認識する場合、顔の特徴(目、鼻、口など)を抽出します。
3.1.3 アルゴリズム選択
機械学習にはさまざまなアルゴリズムがあり、適切なアルゴリズムの選択が重要です。教師あり学習、教師なし学習、強化学習など、問題の種類に応じて適切なアルゴリズムを選びます。
3.1.4 学習と評価
モデルはトレーニングデータセットを使用して学習されます。学習プロセスは、モデルがデータに適合し、パターンを学ぶ過程です。学習後、モデルは評価データセットを使用して性能を評価します。評価には精度、再現率、F1スコアなどの指標が使用されます。
3.1.5 モデルの適応と予測
学習済みモデルは、新しいデータに対して予測を行います。モデルはデータのパターンを認識し、未知のデータに対して予測を生成します。例えば、スパムメールフィルターは、新しいメールがスパムか否かを予測します。
3.1.6 モデルの評価と調整
モデルの性能は定期的に評価され、必要に応じて調整されます。新しいデータや変化した環境に対応するために、モデルの改善や更新が行われます。
機械学習は多くのアプリケーションに適用され、自然言語処理、画像認識、予測分析、自動運転などの分野で成功しています。これらの基本原則は、機械学習の理解と実装に役立ちます。
ディープラーニングの概要
ディープラーニングは、機械学習の一分野であり、深層ニューラルネットワーク(Deep Neural Networks)と呼ばれる多層の人工ニューロンから成るモデルを使用する手法です。以下は、ディープラーニングの概要です。
3.2.1 ニューラルネットワーク
ディープラーニングの基盤となるのは、ニューラルネットワークです。ニューラルネットワークは、脳の神経細胞(ニューロン)の仕組みを模倣して設計され、情報処理に用いられます。ニューラルネットワークは、多くの層(隠れ層)から成り立ち、各層は複数のニューロンで構成されています。
3.2.2 深層ニューラルネットワーク
ディープラーニングは、特に多層のニューラルネットワーク(深層ニューラルネットワーク)を用いています。深層ニューラルネットワークは、情報を多層で抽象化し、非常に複雑なパターンや特徴を学習することができます。これにより、高度なタスクの自動化が可能となります。
3.2.3 学習と特徴抽出
ディープラーニングの特徴は、モデルが自動的に特徴を抽出し、階層的な特徴表現を学習する能力です。これは、人間が手動で特徴を設計する必要がないため、データ駆動型アプローチとして強力です。ディープラーニングモデルは、多くのパラメータを調整してデータに最適化されます。
3.2.4 教師あり学習と教師なし学習
ディープラーニングは教師あり学習と教師なし学習の両方に適用できます。教師あり学習では、ラベル付きデータを使用してモデルを訓練し、分類や予測を行います。一方、教師なし学習では、ラベルがないデータからパターンやクラスタを発見します。
3.2.5 応用分野
ディープラーニングは、画像認識、音声認識、自然言語処理、ゲームプレイ、自動運転、医療診断など多くの分野で成功しています。例えば、畳み込みニューラルネットワーク(CNN)は画像認識で優れた成績を収め、リカレントニューラルネットワーク(RNN)は自然言語処理に使用されます。
ディープラーニングは、大規模なデータセットと高性能なハードウェア(GPUなど)の利用が普及し、AIの進化をけん引しています。以下は、ディープラーニングの応用分野のいくつかです。
- 画像認識: ディープラーニングは、畳み込みニューラルネットワーク(CNN)を用いて画像認識に成功しています。これを活用して、自動車の運転補助システムやセキュリティカメラの顔認識など、さまざまなアプリケーションで利用されています。
- 自然言語処理: リカレントニューラルネットワーク(RNN)やトランスフォーマーモデルを用いたディープラーニングは、自然言語処理タスクで大きな進展を遂げています。これにより、機械翻訳、テキスト生成、質問応答システムなどが向上しました。
- 自動運転: ディープラーニングは、自動運転車の分野でも重要な役割を果たしています。センサーデータからの情報をもとに、車両が周囲の状況を理解し、安全な運転判断を行います。
- 医療診断: ディープラーニングは医療分野での診断支援にも利用されており、画像診断や病理学の分野で高い精度を示しています。例えば、X線やMRI画像から異常を検出するのに役立ちます。
- ゲームプレイ: ディープラーニングは、囲碁や将棋、ビデオゲームなどのゲームで人間プレイヤーに勝つために使用されます。AlphaGoやAlphaZeroの成功は、AIのゲームプレイにおける優越性を示しました。
ディープラーニングの成功には、大規模なデータセットへのアクセス、高性能な計算資源、効果的なアルゴリズムの開発が不可欠です。今後もディープラーニングはAI技術の中核として、新たな応用分野で進化し続けるでしょう。
AIの種類
強化学習
4.1 強化学習の概要
強化学習は、機械学習の一分野であり、エージェント(Agent)が環境と対話しながら最適な行動を学習するための手法です。このアプローチは、報酬を最大化するための行動戦略を見つけることを目指します。以下は、強化学習の特徴と要素です。
4.1.1 エージェント
エージェントは強化学習の主要な要素で、問題を解決しようとする主体です。例えば、ロボット、ゲームプレイヤー、自動運転車などがエージェントとして考えられます。
4.1.2 環境
エージェントは環境と対話します。環境はエージェントが影響を及ぼす対象であり、エージェントの行動に反応します。環境は外部世界であることもありますし、ゲームボードやシミュレーション環境であることもあります。
4.1.3 行動
エージェントはある状況で行動を選択します。これらの行動は、エージェントの意思決定を表します。例えば、ゲームプレイヤーがチェスの駒を動かす行動、自動運転車が車線を変更する行動などです。
4.1.4 報酬
エージェントは環境から報酬を受け取ります。報酬はエージェントの行動の質を評価するための指標で、目標は累積報酬を最大化することです。報酬はポジティブ(良い行動に対する報酬)またはネガティブ(悪い行動に対する罰)の形で提供されます。
4.1.5 方策
エージェントの行動戦略は方策(Policy)として表現されます。方策は、与えられた状況でどの行動を選択するかを定義します。強化学習の目標は、最適な方策を見つけることです。
4.2 強化学習のアルゴリズム
強化学習にはさまざまなアルゴリズムがありますが、最も代表的なものは次のものです。
4.2.1 Q学習
Q学習は、エージェントが行動価値(Q値)を推定し、最適な行動を見つけるための方法です。エージェントは環境との相互作用を通じてQ値を更新し、報酬を最大化するように行動します。Q学習は非常に効果的であり、教育ロボットや制御システムなどの領域で使用されています。
4.2.2 ポリシーグラディエント法
ポリシーグラディエント法は、方策を直接最適化する方法です。エージェントは方策を確率的に選択し、報酬を最大化するために方策パラメータを更新します。このアプローチは、ロボティクスやディープラーニングにおいて高度な制御を実現するために使用されます。
4.3 強化学習の応用
強化学習は幅広い応用分野で利用されています。以下は、一部の応用例です。
- ゲームプレイ: 強化学習は、AlphaGoやDota 2のOpenAI Fiveなど、さまざまなゲームで強力なプレイヤーを生み出しました。
- 自動運転: 自動運転車は、強化学習を使用して交通ルールに従いながら安全に運転する方法を学習します。
- 金融取引: 株式取引や仮想通貨取引などの金融分野では、強化学習を用いて最適な取引戦略を見つける試みが行われています。
- 医療: 強化学習は、がん治療の最適化や薬剤の投与量の最適化など、医療領域での最適化にも応用されています。
強化学習は、エージェントが環境と対話しながら学習するため、非常に強力な学習方法として広く認識されています。将来的には、より多くの領域での応用が期待されています。
教師あり学習と教師なし学習
4.4 教師あり学習
4.4.1 概要
教師あり学習(Supervised Learning)は、機械学習の一形態で、ラベル付きデータを使用してモデルを訓練し、新しいデータに対する予測や分類を行う方法です。教師あり学習では、入力データとそれに対応する正解ラベル(目標値)のペアを使用してモデルをトレーニングします。モデルは、与えられた入力データから正しい出力を予測できるように学習します。
4.4.2 応用例
教師あり学習は多くの実世界の問題に適用されています。以下はいくつかの応用例です。
- 分類: あるデータポイントを予め定義されたクラスまたはカテゴリに分類するタスク。例えば、メールが「スパム」または「非スパム」かを判定するスパムフィルター。
- 回帰: 入力データから数値を予測するタスク。例えば、住宅価格の予測や株価の予測。
- 画像認識: 画像内のオブジェクトや特徴を識別するタスク。例えば、顔認識、病理学的な細胞の異常検出など。
4.5 教師なし学習
4.5.1 概要
教師なし学習(Unsupervised Learning)は、ラベル付けされていないデータから構造やパターンを発見するための機械学習アプローチです。この方法では、モデルはデータセット内の共通性や隠れた構造を抽出し、データをクラスタリングしたり、次元削減を行ったりします。
4.5.2 応用例
教師なし学習は多くの分野で利用されています。以下はいくつかの応用例です。
- クラスタリング: 似たようなデータポイントをグループにまとめるタスク。例えば、顧客セグメンテーションや生物学的データのクラスタリング。
- 次元削減: 高次元のデータを低次元に圧縮するタスク。これにより、データの視覚化や特徴抽出が容易になります。主成分分析(PCA)はその一例です。
- 異常検出: 正常なデータから学習し、異常なデータポイントを検出するタスク。セキュリティログの異常検出や不正クレジットカードの取引検出など。
4.6 教師あり学習と教師なし学習の違い
教師あり学習と教師なし学習の主な違いは、データに対するラベルの有無と、それに伴う学習のアプローチです。
- データラベルの有無: 教師あり学習では、トレーニングデータには正解ラベルが付いており、モデルはこれらのラベルを使って学習します。一方、教師なし学習では、データにはラベルが付いていないか、ラベルが無視されます。モデルはデータ自体の構造やパターンを抽出しようとします。
- 学習アプローチ: 教師あり学習では、モデルは入力データと正解ラベルの関連性を学びます。これにより、新しいデータに対する予測が可能になります。教師なし学習では、モデルはデータ内の隠れた構造やクラスタを発見しようとします。予測の対象は通常ありません。
- タスクの例: 教師あり学習の例には、手書き数字の認識(数字の画像と正解ラベルが提供される)、メールのスパムフィルタ(メールのテキストと「スパム」または「非スパム」のラベルが提供される)などがあります。一方、教師なし学習の例には、カスタマーセグメンテーション(購買履歴データのみが提供され、ラベルはない)、トピックモデリング(大量のテキストデータからテーマを抽出)などがあります。
- 教師あり学習の制約: 教師あり学習は正解ラベルが必要であり、データのラベリングにコストと時間がかかる場合があります。また、ラベルが誤っている場合、モデルの品質に悪影響を及ぼす可能性があります。
- 教師なし学習の柔軟性: 教師なし学習はラベルの不在に対して柔軟であり、データから新たな知識を抽出しやすい特徴があります。データの潜在的な構造を発見するため、探索的データ分析にも適しています。
どちらの学習方法も、それぞれのタスクや問題に合わせて選択されます。さらに、これらのアプローチを組み合わせてセミ教師あり学習や強化学習など、より高度な学習方法が開発されています。
自己教師あり学習
4.7 自己教師あり学習の概要
自己教師あり学習は、機械学習の一種で、ラベル付けされたデータ(教師データ)を使用せずにモデルをトレーニングする手法です。代わりに、モデルはデータ内から自己生成されたラベル(教師信号)を使用して学習します。このアプローチは、ラベル付けデータの不足やコストが高い場合に特に役立ちます。
自己教師あり学習は、モデルが入力データの特徴や構造を理解し、その特性を学習することを目指します。具体的には、以下の方法が一般的に使用されます。
4.7.1 ラベルの自己生成
自己教師あり学習では、元のデータからラベルを自動的に生成するプロセスが含まれます。このため、ラベル付けが必要ないため、大規模なデータセットを利用できる場合でも、データラベルのコストを削減できます。
4.7.2 予測課題
一般的なアプローチは、入力データの一部を非表示にし、モデルにそれを予測させる「予測課題」を与えることです。例えば、テキストデータから一部の単語を隠し、モデルにそれらの単語を予測させるタスクがあります。このプロセスにより、モデルはテキストデータ内の文脈や意味を理解することができます。
4.7.3 特徴抽出
自己教師あり学習を使用すると、モデルはデータから有用な特徴を自動的に抽出できます。これにより、後続のタスクで特徴エンジニアリングの必要性が減少し、モデルの性能が向上します。
4.8 自己教師あり学習の応用
自己教師あり学習は、以下のような多くの応用分野で利用されています。
- 自然言語処理(NLP): 自然言語の文脈や意味を理解し、テキストデータの表現学習に使用されます。例えば、BERT(Bidirectional Encoder Representations from Transformers)は自己教師あり学習を用いたNLPモデルの一例です。
- 画像処理: 画像内の特徴や構造を理解し、画像認識やセグメンテーションタスクに適用されます。例えば、画像の部分を隠し、モデルにそれらの部分を予測させる方法があります。
- 音声処理: 音声データから音響特徴を学習し、音声認識や音声生成タスクに役立ちます。
4.9 自己教師あり学習の利点
自己教師あり学習の利点は次のようにまとめられます。
- データラベルの不要: 通常の教師あり学習ではラベル付けが必要ですが、自己教師あり学習ではラベルを自動生成できるため、ラベリングコストが低減します。
- 大規模なデータセットの活用: 自己教師あり学習は大規模な未ラベルデータセットを活用でき、モデルの性能向上に寄与します。
- 特徴学習: モデルは特徴抽出を学習するため、特徴エンジニアリングの手間が省かれます。
自己教師あり学習は、データの豊富な領域で有望なアプローチとなりつつあり、AIのさらなる進化を支えています。
AIの応用分野
自動運転車
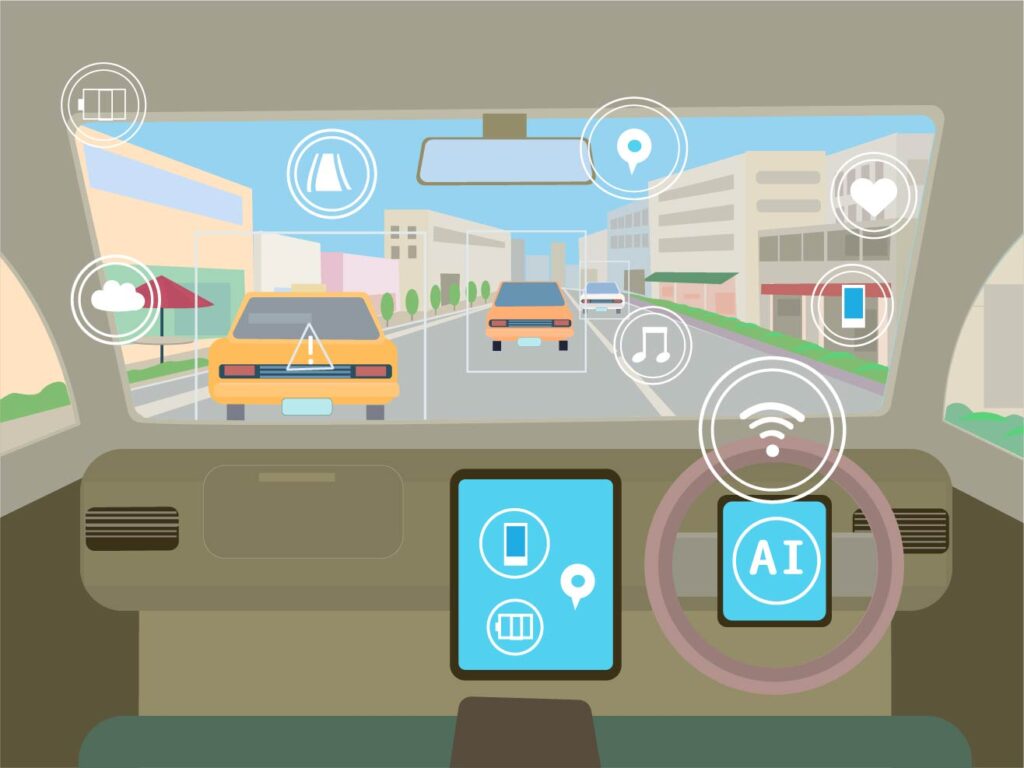
5.1 自動運転車の概要
自動運転車は、AI(人工知能)技術を駆使して、人間の運転手に代わり、自律的に車を運転するシステムです。この技術は、自動車産業に革命をもたらし、交通安全性、効率性、快適性を向上させ、将来の交通システムを変革する可能性があります。
5.2 自動運転車の主要な要素
5.2.1 センサー技術
自動運転車は、周囲の状況を正確に把握するために多くのセンサーを使用します。これらのセンサーには、以下のようなものがあります。
- LiDAR(Light Detection and Ranging): レーザー光線を使って物体の位置を計測し、高精度の3D地図を作成します。LiDARは障害物検出に優れています。
- カメラ: 車の周囲のビジュアル情報を収集し、道路標識、信号、他の車両、歩行者などを認識します。
- レーダー: 障害物の位置と速度を測定し、遠くの物体や悪天候下でも信頼性のあるデータを提供します。
- 超音波センサー: 近距離の障害物検出に使用され、駐車や低速での移動時に重要です。
5.2.2 制御システム
自動運転車の制御システムは、センサーデータを基に車両の速度、方向、アクセル、ブレーキを制御します。これらの制御システムはリアルタイムでデータを処理し、安全かつ効率的な運転を実現します。
5.2.3 ソフトウェアと機械学習
AIソフトウェアと機械学習アルゴリズムは、センサーデータの解釈、道路上のオブジェクトの認識、車両の航路計画、制御システムの最適化など、自動運転車の複雑な機能を実現します。深層学習モデルや強化学習アプローチは、自動運転において特に重要です。
5.3 自動運転車の応用
5.3.1 交通安全性向上
自動運転車は、運転時のヒューマンエラーに起因する交通事故を減少させる潜在的な効果を持っています。センサーとAIによる常に警戒し、反応する能力により、事故を回避する可能性が高まります。
5.3.2 交通効率向上
自動運転車は、交通効率の向上にも寄与します。車両同士の通信や交通制御システムと連携し、交通の滞りを減らし、渋滞を軽減することが期待されています。
5.3.3 モビリティの改善
高齢者や障害者など、運転が難しい人々のモビリティを向上させるのに役立ちます。自動運転車は、ドライバーのライセンスがない人々にとっても独立した移動手段を提供します。
5.4 課題と課題解決
自動運転車の実現にはいくつかの課題が残されています。その中には、法的規制、安全性の確保、倫理的な問題、データプライバシーの配慮などが含まれます。また、自動運転車と人間ドライバーの混在する道路環境における挙動の調整も重要な問題です。
これらの課題に対処しながら、自動運転車技術は着実に進化し、将来の交通システムに大きな変革をもたらす可能性があります。継続的な研究開発と協力が、自動運転車の実現に向けた鍵となります。
医療診断
5.5 医療診断の概要
医療診断におけるAIの応用は、医療分野における診断の正確性と効率性を向上させ、患者の健康管理に革命をもたらしています。AI技術は、医療画像解析、疾患の早期検出、治療計画の最適化、臨床意思決定の支援など、多くの側面で医療診断に活用されています。
5.6 医療診断におけるAIの主要な要素
5.6.1 医療画像解析
AIは、X線、MRI、CTスキャン、超音波などの医療画像を解析する際に重要な役割を果たしています。以下は、AIが医療画像解析において適用される方法の例です。
- 腫瘍検出: AIアルゴリズムは、腫瘍やがん組織を画像から検出し、その大きさや位置を特定します。これにより、がんの早期発見と治療の最適化が可能になります。
- 病変の追跡: AIは、病変や傷害の進行をモニタリングし、治療効果を評価します。例えば、患者の糖尿病性網膜症の進行を追跡するためにAIが使用されます。
5.6.2 生体データ解析
AIは、生体データ(血液検査、遺伝子情報など)を分析して、疾患のリスク評価や個別化された治療法の提案に役立てられます。以下は、AIが生体データ解析において適用される方法の例です。
- 遺伝子解析: AIは遺伝子情報を解析して、個別の遺伝的リスクや遺伝的要因に基づいた治療法を提案します。がんの遺伝子プロファイル解析などがその一例です。
- 血液検査データ: 血液検査のデータを解析し、糖尿病や心臓病などの疾患のリスクを評価します。また、治療効果をモニタリングするためにも使用されます。
5.6.3 臨床意思決定支援
AIは医療の臨床意思決定をサポートするために設計されたツールとしても使用されます。これらのシステムは、最新の医学文献や患者のデータを考慮して、医師や看護師に適切な診断や治療提案を提供します。
- 診断支援: AIは症状と臨床データに基づいて、潜在的な診断を提案し、医師の診断プロセスを補完します。
- 治療計画の最適化: 患者の個別の医療データに基づいて、最適な治療計画を提案します。これにより、治療の効果が最大化されます。
5.7 医療診断の利点
AIを医療診断に導入することには多くの利点があります。
- 正確性の向上: AIは高度な画像解析とデータ処理能力を持ち、正確な診断とリスク評価を提供します。
- 早期検出: AIは病変や異常を早期に検出する能力を持ち、治療の早期開始を可能にします。
- 個別化された治療: AIは患者の個別データを用いて、治療計画を最適化し、適切な治療法を提案します。これにより、治療の効果が向上し、副作用が最小限に抑えられます。
- 効率性の向上: AIは大量の医療データを効率的に処理し、医療従事者の負担を軽減します。これにより、医師や看護師はより多くの患者に対応できるようになります。
- 継続的なモニタリング: AIは患者のデータを継続的にモニタリングし、状態の変化を早期に検出します。これにより、慢性疾患の管理やリモートヘルスケアが向上します。
- 知識の共有: AIは大規模なデータセットを分析し、医療知識を蓄積します。この知識は医療従事者間で共有され、診断や治療の向上に寄与します。
5.8 課題と課題解決
医療診断におけるAIの導入にはいくつかの課題が存在します。
- データプライバシー: 医療データは非常に機密性が高く、患者のプライバシーを保護する必要があります。適切なデータセキュリティ対策が必要です。
- 規制と法的課題: 医療分野は高度に規制されており、AIの医療診断への導入には規制当局の承認が必要です。また、診断が誤って行われた場合の責任についても法的な課題があります。
- データ品質: AIの診断精度は、訓練データの品質に大きく依存します。正確なデータ収集とラベリングが必要です。
- 人間との協力: 医師や看護師との協力が不可欠です。AIはツールとして使用され、医療従事者の判断を補完する役割を果たします。
医療診断におけるAIの実用化に向けては、これらの課題に対処しながら、科学的な検証と倫理的なガイドラインの確立が進められています。 AI技術の進化により、医療診断の精度と効率性が向上し、患者の健康状態を改善するための新たな道が開かれています。
金融予測
5.9 金融予測の概要
金融予測におけるAIの応用は、金融業界における意思決定プロセスを向上させ、資産価格の変動、リスク管理、投資戦略の最適化など、多くの金融関連タスクに貢献しています。AI技術は大量のデータを迅速に分析し、複雑なパターンを検出する能力により、金融市場の参加者に競争上の優位性を提供しています。
5.10 金融予測におけるAIの主要な要素
5.10.1 データ分析と予測モデル
金融予測において、AIは以下のような方法で利用されます。
- 市場データの分析: AIは株式市場、外国為替市場、商品市場などの市場データを分析し、価格の変動パターンや相関関係を把握します。
- 予測モデルの構築: AIは過去のデータを使用して予測モデルを構築し、将来の価格動向やリスクを評価します。このプロセスには機械学習アルゴリズムが頻繁に使用されます。
5.10.2 自然言語処理(NLP)
金融予測において、AIはニュース記事、社会的メディアの投稿、企業報告書などのテキストデータを分析し、市場に影響を与える情報やトレンドを抽出します。自然言語処理技術は、テキストから情報を抽出し、市場参加者に提供します。
5.10.3 リスク管理
金融機関はリスク管理にAIを活用しています。AIはリスク評価モデルを構築し、信用リスク、市場リスク、操作リスクなどの異なるタイプのリスクをモニタリングします。また、不正取引の検出や防止にも役立てられます。
5.11 金融予測の利点
AIを金融予測に導入することには多くの利点があります。
- 高度な予測能力: AIは大規模なデータセットを迅速に分析し、市場のパターンやトレンドを特定する能力により、正確な予測を提供します。
- リアルタイムの意思決定: AIはリアルタイムデータを利用して、迅速な意思決定を支援します。これは市場の瞬時の変動に対応するために重要です。
- リスク削減: AIはリスク評価とリスク管理を強化し、金融機関や投資家に対するリスクの認識を高めます。
- 効率の向上: AIは金融業務の効率を向上させ、自動化されたプロセスによりコストを削減します。
5.12 課題と課題解決
金融予測におけるAIの利用にはいくつかの課題が存在します。
- データの品質: AIの予測モデルは高品質なデータに依存します。誤ったデータやノイズがモデルの精度に影響を及ぼす可能性があります。
- 過剰適合: 過去のデータに過度に適合するモデルは、将来の予測の信頼性を低下させる可能性があります。
- 規制と倫理: 金融市場は規制が厳格であり、AIの使用に関する法的および倫理的な課題が存在します。透明性や説明責任が重要です。
- 市場の非効率性: AIは市場に対する情報のアシンメトリーを強調する可能性があり、非効率性を増加させることがあります。
これらの課題に対処しながら、金融業界はAIを活用し、正確な金融予測と効果的なリスク管理を実現し、市場競争力を維持するための戦略を進化させています。
自然言語処理

5.13 自然言語処理の概要
自然言語処理(Natural Language Processing、NLP)は、AI技術を用いて人間の自然言語を理解し、解釈、生成する分野です。NLPはテキストデータや音声データを処理し、情報の抽出、機械翻訳、感情分析、質問応答システム、要約生成など多くのタスクに応用されています。以下は、NLPの主要な要素と応用分野のいくつかです。
5.14 NLPの主要な要素
5.14.1 テキストデータ処理
NLPの基本的な要素の一つは、テキストデータの処理です。テキストデータはトークン化、品詞タグ付け、構文解析などの手法を使用して構造化され、コンピュータが理解できる形に変換されます。
- トークン化: テキストを単語や句に分割するプロセスです。例えば、文を単語に分割することがトークン化の一例です。
- 品詞タグ付け: 単語に品詞(名詞、動詞、形容詞など)を割り当てるプロセスです。品詞タグ付けは文法解析や意味解析に役立ちます。
5.14.2 意味理解
NLPはテキストデータの意味を理解するための技術も提供します。意味理解はテキストの意味や文脈を把握し、文や文の間の関係を理解するための手法を含みます。
- 意味解析: テキスト内の語句やフレーズの意味を抽出し、理解します。これは情報検索や感情分析に役立ちます。
- 文脈理解: テキスト内の文脈を考慮して意味を解釈します。文脈は文の前後関係や文書全体の情報を含みます。
5.14.3 自然言語生成
NLPは自然言語の生成にも使用されます。自然言語生成は、コンピュータが自然な言語でテキストを生成するプロセスで、機械翻訳、要約、文章生成などに応用されます。
- 機械翻訳: 一つの言語から別の言語へのテキストの自動翻訳を実現します。例えば、英語から日本語への翻訳がその一例です。
- 要約生成: 長文を要約し、重要な情報を抽出するプロセスです。要約生成は大量の情報から要約を作成する際に有用です。
5.15 NLPの応用分野
NLPは多くの応用分野で活用されています。
5.15.1 質問応答システム
NLPを用いた質問応答システムは、ユーザーの質問に対して適切な回答を生成するために使用されます。これは仕事上の情報検索やバーチャルアシスタントとしての応用があります。
- 情報検索: NLPベースの質問応答システムは、大規模なデータベースやウェブから情報を抽出し、ユーザーが特定の情報を素早く見つけるのに役立ちます。例えば、医療情報、旅行情報、法的アドバイスなどの分野で使用されます。
5.15.2 感情分析
感情分析は、テキストデータから感情や評価を抽出するためのNLPの応用です。ソーシャルメディアのコメント、商品レビュー、顧客フィードバックなど、大量のテキストデータから情報を取り出し、感情を分類することができます。
- 顧客サポートとレビュー分析: 企業は顧客の感情や評価を把握し、製品やサービスの改善に役立てます。また、商品の評判をモニタリングし、消費者の反応に対応します。
5.15.3 情報抽出
情報抽出は、大規模なテキストデータから特定の情報を抽出するためのNLP技術です。これにより、重要な情報の自動収集や知識ベースの構築が可能となります。
- ニュース記事からの情報抽出: NLPはニュース記事から重要な情報を抽出し、要約したり、特定のトピックに関する記事を自動的に収集するために使用されます。
5.15.4 言語モデリング
NLPは言語モデリングにも応用され、自然な対話システムやテキスト生成に使用されます。最近の進歩により、より自然な対話エージェントが開発され、カスタマーサポート、教育、エンターテイメントなどの領域で活用されています。
5.16 NLPの利点
NLPを使用することにはいくつかの利点があります。
- 効率の向上: NLPは大量のテキストデータを迅速に処理し、情報を取得、要約、分析する能力を提供します。これにより、情報の処理速度と効率が向上します。
- 洞察の獲得: NLPはテキストデータから洞察を獲得し、意思決定プロセスを支援します。例えば、市場トレンドの把握や競合情報の収集があります。
- 自動化: NLP技術はタスクの自動化を可能にし、作業効率を向上させます。これにより、コスト削減と生産性向上が実現します。
- 多言語対応: NLPは複数の言語に適応できるため、国際的なコミュニケーションや情報アクセスに役立ちます。
5.17 課題と課題解決
NLPの応用にはいくつかの課題が存在します。
- 多義性: 自然言語には多義性があり、単語やフレーズの意味が文脈に依存することがあります。これを解決するために、文脈を理解するNLPモデルが必要です。
- データの質と量: NLPモデルは大規模なトレーニングデータを必要とすることがあり、データの質と量の問題があります。特に低リソース言語の場合、データ収集が課題となります。
- 倫理とプライバシー: NLPは個人情報を含むテキストデータを扱うため、倫理的な配慮とプライバシー保護が必要です。データの適切な取り扱いと匿名化が求められます。
- バイアスと公平性: NLPモデルはトレーニングデータから学習するため、バイアスを持ち込む可能性があります。公平性の確保とバイアスの除去が重要です。
AI倫理と課題
データプライバシー

6.1 データプライバシーの重要性
データプライバシーは、AI倫理と技術の発展において極めて重要なテーマです。データプライバシーは、個人の情報とその使用に関連する倫理的な考慮事項を指し、以下の点が含まれます。
- 個人情報の保護: 個人の識別可能な情報(氏名、住所、電話番号、メールアドレスなど)の適切な保護が必要です。これにより、個人が不正な利用やデータ侵害から保護されます。
- 同意と透明性: 個人情報の収集と使用についての透明性が必要で、個人は自分のデータがどのように使用されるかを理解し、同意できる必要があります。
- データ最小化: データ収集は必要最小限に抑えられるべきであり、目的に応じてデータを収集する原則が遵守されるべきです。
- セキュリティ: 収集されたデータは適切に保護され、不正アクセスやデータ漏洩から守られるべきです。
6.2 AIとデータプライバシーの関係
AI技術はデータを駆使して学習し、個人のデータを活用することがあります。そのため、データプライバシーに関連するいくつかの倫理的な課題が浮上しています。
6.2.1 データの収集と目的
多くのAIシステムは、大規模なデータセットから学習します。しかし、これらのデータセットはどのように収集され、どの目的で使用されるかに関する倫理的な問題があります。データの収集は同意を得ることやデータ最小化原則を遵守することが重要です。
6.2.2 データの匿名化と再識別
データを匿名化することは、個人を特定できないようにするための重要な手法です。しかし、匿名化されたデータから個人を再識別することができるというリスクも存在します。このため、十分なセキュリティ対策が求められます。
6.2.3 プロファイリングとバイアス
AIはデータをもとにユーザーのプロファイルを作成し、個別にカスタマイズされたコンテンツや広告を提供します。しかし、このプロファイリングはバイアスを含むことがあり、人々の意思決定に影響を与える可能性があります。バイアスの排除と透明性が重要です。
6.3 データプライバシーの課題
データプライバシーに関連する課題は以下のようになります。
6.3.1 データ侵害
データプライバシーの最も顕著な課題の一つは、データ侵害です。ハッカーや不正アクセス者によって個人情報が盗まれると、その情報が悪用される可能性があります。データセキュリティの向上が必要です。
6.3.2 オンライン追跡
オンラインでの活動は広告主やプラットフォームによって追跡され、個人の行動プロファイルが作成されます。これにより、ユーザーはオンラインでのプライバシーを懸念することがあります。プライバシー保護の法的枠組みの整備が求められます。
6.3.3 バイアスとディスクリミネーション
AIのプロファイリングや意思決定において、バイアスが影響を与えることがあり、人種、性別、年齢などに関するディスクリミネーションが起こる可能性があります。これに対処するために、アルゴリズムの公平性を確保する方法が研究されています。
6.4 データプライバシーの保護
データプライバシーの保護には以下のアプローチがあります。
6.4.1 法的規制
多くの国でデータプライバシーに関する法的規制が存在し、個人情報の収集、処理、保護に関するルールが定められています。一般データ保護規則(GDPR)やカリフォルニア消費者プライバシー法(CCPA)などがその例です。
6.4.2 プライバシー保護技術
プライバシー保護技術は、データを匿名化したり、暗号化したりすることで、データプライバシーを強化するのに役立ちます。セキュリティ対策の一環として、データの保護と安全性を高めるために使用されます。
6.4.3 ユーザーの教育と意識向上
データプライバシーの重要性を一般のユーザーに認識させ、プライバシーに対する意識を高めることも重要です。ユーザーに対して、どのようにデータが収集され、使用されるかを説明し、同意を得る手法が推奨されます。
6.4.4 倫理的設計
AIシステムを設計する際に、倫理的な側面を考慮に入れることが重要です。データの適切な取り扱い、バイアスの排除、透明性の提供などが倫理的設計の一環として検討されます。
6.5 データプライバシーの未来
データプライバシーに関する議論と課題は今後も進化し続けるでしょう。AI技術の発展に伴い、個人データの保護と合法的な使用のバランスを取ることが求められます。また、新たなプライバシー保護技術や法的規制が登場する可能性が高いです。
データプライバシーは、AIの発展と利用拡大において不可欠な側面であり、ユーザーと企業の信頼を確保するために重要な要素です。個人の権利とプライバシーを尊重し、透明性と責任あるデータの取り扱いが継続的に強調されるでしょう。
人間の仕事への影響

6.1 AIと雇用の未来
AI(人工知能)技術の急速な進歩は、労働市場に大きな変革をもたらしました。これまでにない速さで自動化、ロボティクス、機械学習が普及し、これらの技術は多くの産業で労働力としての人間に代わる可能性を持っています。以下に、AIが人間の仕事に与える影響について考えてみましょう。
6.2 仕事の自動化
AIは単純で反復的なタスクを自動化するのに非常に適しており、これによって多くの職種で効率が向上しています。例えば、製造業において、ロボットや自動機械が物理的な作業を担当し、工場の生産性を向上させています。同様に、データエントリーやルーチンなデータ分析などのオフィス業務もAIによって自動化されています。
6.3 転職と再教育の必要性
AIによる仕事の自動化は、一部の職種にとっては仕事の喪失をもたらす可能性があります。このため、労働者は新しい職業やスキルを習得する必要が生じます。転職や再教育が不可欠であり、個人と社会全体の適応能力が求められます。
6.4 AIと人間の協働
AI技術は完全に人間の代わりになるだけでなく、人間と協力して作業する機会も提供しています。例えば、ロボットと人間が協力して工場でタスクを実行する場面や、AIアシスタントが医療専門家に診断支援を提供する場面があります。これにより、作業の効率性が向上し、新しい職種が生まれる可能性があります。
6.5 倫理的配慮
AIの普及に伴い、倫理的な配慮がますます重要になっています。特に、AIによる仕事の自動化が進行する場合、以下の点に留意する必要があります。
6.5.1 失業のリスク
一部の職種では、AIによる自動化が失業のリスクを増加させる可能性があります。特に低賃金の労働者や単純作業の従事者が影響を受けやすいです。
6.5.2 スキルの不一致
新たな仕事やスキルが求められる場合、労働者がこれに適応するための十分なトレーニングと教育を受けられるようにする必要があります。スキルの不一致が解消されないと、一部の人々は職を失う可能性が高まります。
6.5.3 人間らしい特性の重要性
AIはタスクの自動化に優れていますが、人間らしい特性、例えば創造性、感情理解、倫理的判断などはまだAIには不得意です。これらの特性が今後の仕事市場でますます重要になる可能性があります。
6.6 新たな職種の出現
一方で、AIの発展は新たな職種の出現をもたらすこともあります。AIの設計、開発、保守、監視、倫理的な指導などを担当する職種が増加しています。AIと共に働くためのスキルや知識を持つ人々は、新しいキャリアの機会を追求することができます。
6.7 まとめ
AI技術の進化は労働市場に影響を及ぼし、一部の職種を変えるか、取って代わるかもしれません。しかし、AIと人間の協働や新たな職種の出現も期待されており、適応力を持つことが重要です。倫理的な配慮と教育への投資が、AIとの共存を実現するために不可欠です。
偏ったデータ
6.1 偏りの問題
AIシステムはデータに基づいて学習し、意思決定を行います。しかし、データセットに偏りがある場合、AIの学習と意思決定に問題が生じる可能性があります。偏ったデータは、AI倫理における重要な課題の一つです。
6.2 偏りの種類
偏りはさまざまな形で現れます。
6.2.1 サンプルの偏り
データセットが特定の属性やクラスに対して不均衡である場合、AIモデルは頻繁に出現するクラスに偏った予測を行う可能性があります。これは、マイナリティクラスの誤分類や無視を引き起こすことがあります。
6.2.2 ラベルの偏り
データのラベル付けが不正確である場合、AIモデルは正確な予測を行えなくなります。例えば、センサーデータのラベル付けが誤っている場合、モデルは誤った情報を学習します。
6.2.3 サンプリングバイアス
データ収集プロセスにおいて、特定の集団や地域からのデータが不足している場合、AIモデルはその集団に対して不正確な予測を行う可能性があります。これは、社会的なバイアスを強化する要因となります。
6.3 偏りの影響
偏ったデータがAIモデルに与える影響は深刻です。
6.3.1 不公平な予測
偏ったデータに基づくAIモデルは、特定の集団や属性に対して不公平な予測を行うことがあります。例えば、人種や性別に基づく差別的な予測が行われる可能性があります。
6.3.2 正確性の低下
偏ったデータに基づくAIモデルは、一般的な適用性が低下し、正確性が低くなることがあります。これは、医療診断、金融予測、法的意思決定などの領域で特に危険です。
6.3.3 倫理的課題
偏りが生じた場合、AIの使用に関連する倫理的な問題が浮上します。倫理的な配慮が欠けることが、個人や社会への潜在的な害をもたらす可能性があります。
6.4 偏りの解決策
偏りの問題を解決するためには、以下のアプローチが取られます。
6.4.1 データの収集とラベル付けの改善
データ収集プロセスを改善し、データセットの偏りを最小化します。正確なラベル付けと、多様な属性やクラスをカバーするデータの収集が重要です。
6.4.2 バイアスの検出と軽減
AIモデルが偏りを持つデータに対してバイアスを示す可能性があるため、バイアスの検出と軽減が重要です。適切なアルゴリズムやテクニックを使用して、バイアスを特定し、対処します。
6.4.3 透明性と説明可能性
AIモデルの意思決定過程を透明かつ説明可能にすることで、偏りがどのように影響を及ぼしているかを理解しやすくします。透明性は倫理的な監視と改善に役立ちます。
6.4.4 ダイバーシティとインクルージョン
AIの開発において多様な視点とスキルを持つチームを構築することは、偏りを軽減し、公平なモデルの構築に寄与します。
6.5 まとめ
AIの成功はデータに依存しており、データの偏りは倫理的な問題として深刻な影響を及ぼす可能性があります。偏りを解決するためには、データの収集とラベル付けの改善、バイアスの検出と軽減、透明性の向上、ダイバーシティとインクルージョンなどの取り組みが必要です。AI倫理における偏りの問題は、公平性と正確性を確保するために不可欠な要素です。
AIの学習リソース
オンラインコースと教材
AI(人工知能)に興味を持ち、学習したいと考える人々のために、オンラインコースと教材は非常に貴重な学習リソースとなっています。AIの分野は急速に進化しており、新たな技術やアルゴリズムが日々開発されています。ここでは、AIの学習に役立つオンラインコースと教材について紹介します。
7.1 オンラインコース
7.1.1 Coursera
Courseraは世界中の大学や機関と提携し、高品質なオンラインコースを提供するプラットフォームです。AIに関するコースも豊富で、Stanford Universityやdeeplearning.aiなどの著名な機関から提供されています。例えば、「Machine Learning」や「Deep Learning Specialization」などがあります。
7.1.2 edX
edXも世界的な大学と提携しており、AIのコースを提供しています。MITやHarvardなどの名門大学からのコースが多数あり、「Introduction to Artificial Intelligence」といったコースがあります。
7.1.3 Udacity
Udacityは、実務に焦点を当てたオンラインコースを提供しています。AIプログラミング、機械学習エンジニア、ディープラーニングエンジニアなど、キャリアに関連する専門コースがあります。
7.1.4 Fast.ai
Fast.aiは、機械学習とディープラーニングに特化したオンラインコースを提供し、実践的なスキルを身につけたい人に向いています。コース料金が低いため、手軽に学習を開始できます。
7.2 教材
7.2.1 TensorFlow
TensorFlowはGoogleが開発した機械学習フレームワークで、公式のドキュメンテーションとチュートリアルが豊富に用意されています。TensorFlowを使った機械学習やディープラーニングの学習に適しています。
7.2.2 PyTorch
PyTorchはFacebookが開発した機械学習フレームワークで、Pythonで記述されています。PyTorchの公式ドキュメンテーションやコミュニティの提供するチュートリアルが充実しており、多くのディープラーニングエンジニアに支持されています。
7.2.3 Kaggle
Kaggleはデータサイエンティストと機械学習エンジニア向けのプラットフォームで、コンペティションやカーネル(ノートブック)を通じて学習できます。Kaggleのコンテンツは実践的であり、実データに対するスキルを高めるのに役立ちます。
7.2.4 GitHub
GitHubは多くのAIプロジェクトやオープンソースライブラリのホストとして知られており、コードやノートブックを共有・学習するためのリソースが数多く存在します。AIのコードやプロジェクトを探し、学び、貢献する場所として活用できます。
7.3 自己学習のポイント
AIの学習において成功するためには、以下のポイントに留意することが重要です。
- 目標設定: どの分野に興味があり、どのスキルを磨きたいかを明確にしましょう。
- 実践: 知識を実際のプロジェクトに適用して経験を積むことが大切です。
- コミュニティ参加: オンラインコミュニティやフォーラムで他の学習者と交流し、助け合いましょう。
- 最新情報の追跡: AI分野は急速に進化するため、最新の情報に追随することが必要です。
AIの学習は継続的なプロセスであり、自己学習と探求心が重要です。オンラインコースと教材は、この旅をサポートする貴重なリソースです。
AIに関連する書籍
AI(人工知能)に関連する書籍は、深い知識を獲得したり、特定のトピックについて詳しく学んだりするための貴重なリソースです。以下は、AI学習の際に参考にできる書籍のいくつかです。
7.1 機械学習
7.1.1 “Pattern Recognition and Machine Learning” by Christopher M. Bishop
この書籍は、機械学習の基本原理とアルゴリズムに焦点を当てています。確率論的なアプローチを用いて、パターン認識と機械学習の概念を解説しています。
7.1.2 “Introduction to Machine Learning with Python: A Guide for Data Scientists” by Andreas C. Müller & Sarah Guido
Pythonを使用した機械学習の実践的なガイドです。Scikit-Learnライブラリを活用して、実際のデータに対して機械学習モデルを構築する方法を示しています。
7.2 ディープラーニング
7.2.1 “Deep Learning” by Yoshua Bengio, Ian Goodfellow, and Aaron Courville
ディープラーニングの基本から応用まで、包括的にカバーしている書籍です。著者はディープラーニングの第一人者であり、理論的な側面から実装まで幅広く解説しています。
7.2.2 “Hands-On Machine Learning with Scikit-Learn, Keras, and TensorFlow” by Aurélien Géron
この書籍は、Scikit-Learn、Keras、TensorFlowを使用して実践的な機械学習とディープラーニングを学ぶための手法を提供しています。実際のプロジェクトを通じて学びながら進むスタイルが特徴です。
7.3 AIの倫理と社会的影響
7.3.1 “Weapons of Math Destruction: How Big Data Increases Inequality and Threatens Democracy” by Cathy O’Neil
AIの倫理と社会的影響に焦点を当てた書籍で、アルゴリズムによる社会的不平等やバイアスの問題について議論しています。AIの使用が社会に与える影響を理解するための読み応えのある一冊です。
7.3.2 “AI Superpowers: China, Silicon Valley, and the New World Order” by Kai-Fu Lee
この書籍は、AIの世界的な競争と影響に焦点を当てています。中国とシリコンバレーを中心に、AIの進化と地政学的な影響を詳しく探ります。
7.4 AIの実践とアプリケーション
7.4.1 “Python Machine Learning” by Sebastian Raschka and Vahid Mirjalili
Pythonを使用して機械学習を実践的に学びたい人向けの書籍です。具体的なプロジェクトを通じて、実際のデータセットを使った機械学習の実装方法を示しています。
7.4.2 “Deep Learning for Computer Vision” by Rajalingappaa Shanmugamani
コンピュータビジョンに焦点を当てた書籍で、ディープラーニングを用いた画像処理と認識のアプリケーションについて学びます。
7.5 AIの個別分野
AIの特定の分野に興味がある場合、その分野に特化した書籍を探すこともおすすめです。例えば、自然言語処理(NLP)、ロボティクス、自動運転など、幅広い分野に関する書籍が存在します。
これらの書籍はAIの学習プロセスを補完し、理論から実践まで幅広い情報を提供します。また、自己学習や専門的な知識の獲得に役立つでしょう。AIの分野は急速に進化しており、最新の情報に追随できるよう、定期的に新刊をチェックすることもおすすめです。
コミュニティとフォーラム
AI(人工知能)学習者やプロフェッショナルにとって、コミュニティとフォーラムは重要な学習リソースです。これらのプラットフォームは知識の共有、質問への回答、プロジェクトの共同作業、新しいアイデアの発展に役立ちます。以下は、AI学習者におすすめのコミュニティとフォーラムです。
7.1 Redditのサブレディット
RedditはAIに関する多くのサブレディット(専用のトピックごとのコミュニティ)を提供しており、学習者やエキスパートが情報を共有し、議論を行っています。以下はいくつかの人気のあるAI関連のサブレディットです。
- r/MachineLearning: 機械学習に関する最新の研究論文、トレンド、質問への回答が共有されます。
- r/deeplearning: ディープラーニングに焦点を当てたディスカッションとリソースが提供されています。
- r/artificial: 一般的なAIトピックに関するディスカッションが行われます。
- r/learnmachinelearning: 機械学習初心者向けの質問とアドバイスが受けられます。
7.2 Stack Overflow
Stack Overflowはプログラミングと技術に関する質問と回答のプラットフォームで、AIに関する質問も多く取り扱われています。AIのプログラミングやトラブルシューティングに困った場合、Stack Overflowで質問を投稿し、エキスパートからの支援を受けることができます。
7.3 GitHub
GitHubはオープンソースプロジェクトの共同作業とコード共有の場です。AIに関連する多くのプロジェクトがGitHubでホストされており、コードの閲覧、貢献、共同開発が可能です。また、プロジェクトのイシュートラッキングやディスカッションのための機能も提供しています。
7.4 Kaggle
Kaggleはデータサイエンティストと機械学習エンジニア向けのプラットフォームで、コンペティションやカーネル(ノートブック)の形で学習と共有をサポートしています。Kaggleコミュニティはデータ関連のプロジェクトや問題に対する洞察を共有し、議論する場所です。
7.5 AI関連の専門的なコミュニティ
AIの特定の分野やプロジェクトに関連する専門的なコミュニティも存在します。例えば、自然言語処理(NLP)、コンピュータビジョン、強化学習などの分野に特化したコミュニティがあります。これらのコミュニティに参加することで、特定の領域における深い知識を獲得できます。
AI学習者にとって、コミュニティとフォーラムは知識の拡充、プロジェクトの共同作業、ネットワーキングの機会として非常に重要です。質問をする、他の学習者と共有する、プロジェクトに参加するなど、積極的に参加することでAIのスキルを向上させることができます。
AIの未来展望

AIの進化と未来のトレンド
AI(人工知能)は急速に進化しており、未来の展望は非常に魅力的です。以下は、AIの進化と未来のトレンドについてのいくつかのポイントです。
8.1 自己学習の向上
未来のAIシステムは、より高度な自己学習能力を持つようになるでしょう。現在の機械学習モデルは大量のデータと教師あり学習に依存していますが、将来的には少ないデータからも効果的に学習し、新たなタスクを遂行できるAIが開発されるでしょう。
8.2 汎用AI(AGI)への進化
人間のような一般的な知能を持つAGI(Artificial General Intelligence)への道は長いものですが、研究者たちはこの目標に向かって進歩しています。AGIはさまざまなタスクを理解し、学習し、遂行できるAIを指し、医療診断、自動運転、ロボティクス、クリエイティビティなど多くの分野に革命をもたらすでしょう。
8.3 エッジAIと分散型AI
AIの処理能力はエッジデバイス(スマートフォン、IoTデバイスなど)にも組み込まれ、リアルタイムの処理と判断が可能になります。分散型AIシステムは、ネットワークの遅延を減少させ、セキュリティとプライバシーを向上させるでしょう。
8.4 自然言語処理(NLP)の進化
NLP技術は、より高度な自然な対話を可能にし、異なる言語間のコミュニケーションを向上させるでしょう。AIアシスタントや翻訳ツールはさらに高度になり、異文化間のコミュニケーションを促進します。
8.5 エシカルAIとAI倫理
AIの進化に伴い、エシカルAIとAI倫理の重要性が増しています。倫理的なガイドラインや法的枠組みが整備され、AIの発展が公平で社会的に責任あるものとなることが期待されています。
8.6 AIの産業応用の拡大
AIは様々な産業において利用され、生産性向上、効率化、新たなビジネスモデルの創出などに貢献しています。将来的には、教育、健康医療、エネルギー、農業などでのAIの応用が一層広がるでしょう。
8.7 サステナビリティへの寄与
AIはエネルギー効率や環境への影響を改善するために利用され、サステナビリティへの寄与が期待されます。例えば、エネルギー管理、交通制御、環境モニタリングなどでAIの活用が増えています。
未来のAIは、さらなる革命と進歩をもたらすでしょう。しかし、この進化には倫理的な課題やセキュリティの問題も伴います。持続可能な発展と個人のプライバシー保護に焦点を当てつつ、AI技術の進歩を追い続ける必要があります。
AIの社会的な影響
AI(人工知能)の未来展望は、社会に大きな影響を及ぼすことが予想されます。以下は、AIの社会的な影響についてのいくつかのポイントです。
8.1 雇用と職業の変化
AIの普及により、ある職種は自動化され、新たな職種が創出されるでしょう。一部の業界では、ルーチンな仕事や単純なタスクがAIに取って代わられる可能性があります。しかし、同時にAIの開発、保守、監視に関連する職種も増加するでしょう。教育やトレーニングが重要な役割を果たし、スキルのアップデートと再教育が必要です。
8.2 教育とアクセス
AI技術を活用した教育へのアクセスが向上することが期待されます。個別に合わせた学習体験や、リモート教育の発展により、教育の格差が縮小する可能性があります。しかし、テクノロジーへのアクセスが制限される地域や社会階層も存在し、この問題に対処する必要があります。
8.3 ヘルスケアと医療
AIは医療分野において診断、治療、医療データ解析の向上に貢献します。病気の早期発見や個別治療のカスタマイズが可能になり、医療の効率性が向上するでしょう。しかし、個人の健康データのプライバシーとセキュリティに対する懸念も浮上します。
8.4 エンターテイメントとクリエイティビティ
AIはエンターテイメント業界にも影響を与え、映画、音楽、ゲームなどのクリエイティビティを補完します。AIは新たなアートやメディア形式を生み出し、ユーザーエクスペリエンスを向上させるでしょう。一方で、創造的な職業におけるAIの役割についても議論が続きます。
8.5 倫理とプライバシー
AIの発展に伴い、倫理的な問題とプライバシーの懸念が増加するでしょう。AIの意思決定プロセスの透明性、バイアスの排除、個人データの保護などが重要な課題となります。規制とガイドラインの整備が必要です。
8.6 社会的影響と政策
AIの導入には政策と規制の整備が不可欠です。AIの安全性、エシカルな使用、データの所有権などに関する法律が発展し、AI技術が社会に適切に統合されるためのフレームワークが整備されるでしょう。
未来のAIは、社会のあらゆる側面に影響を与えます。これに備え、倫理的な観点から、教育、プライバシー、医療、雇用などの分野で慎重な検討と調整が必要です。AI技術の進歩は社会に多くの利益をもたらす一方、その影響を最小限に抑え、公平かつ持続可能な未来を築くための努力も不可欠です。
まとめ
AIの要点の振り返り
このブログコンテンツを通じて、AI(人工知能)についての基本的な要点を理解しました。以下は、AIに関する要点を振り返りましょう。
- AIの基本的な定義: AIはコンピューターシステムによる、人間の知識や能力を模倣し、問題を解決する技術です。具体的な例には、画像認識、音声認識、自然言語処理があります。
- AIの歴史: AIは1950年代に始まり、時間の経過とともに進化しました。マイルストーンとして、専門家システム、機械学習、ディープラーニングなどがあります。
- 機械学習とディープラーニング: 機械学習はデータからパターンを学び、予測や意思決定を行う技術です。ディープラーニングは多層のニューラルネットワークを使用して、高度なタスクを実行します。
- AIの種類: 強化学習は環境に対する行動を学びます。教師あり学習はラベル付きデータを使用して予測モデルをトレーニングします。教師なし学習はラベルなしデータからパターンを抽出します。自己教師あり学習は一部のデータからラベルを生成し、モデルをトレーニングします。
- AIの応用分野: AIは自動運転車、医療診断、金融予測、自然言語処理など、さまざまな分野で利用されています。これらの応用により、効率が向上し、新たな可能性が開かれています。
- AI倫理と課題: AIの倫理的な課題には、データプライバシー、人間の仕事への影響、偏ったデータなどがあります。倫理的な使用と課題の克服が重要です。
- AIの学習リソース: AI学習のためのオンラインコース、教材、書籍、コミュニティ、フォーラムが豊富に利用可能です。これらのリソースを活用してスキルを向上させましょう。
- AIの未来展望: AIは自己学習の向上、汎用AI(AGI)への進化、エッジAI、NLPの進化など、未来においても大きな進展が期待されています。しかし、倫理、プライバシー、社会的影響への対処が必要です。
AIは今後の技術進化と社会の変化において中心的な役割を果たすでしょう。AIを理解し、適切に活用するために、継続的な学習と倫理的な考慮が不可欠です。AIの可能性は無限大であり、私たちの生活と社会に革命的な変化をもたらすことでしょう。
AIの重要性と可能性の再強調
AI(人工知能)は現代社会において非常に重要な役割を果たし、未来においてもさらなる可能性を秘めています。このまとめでは、AIの重要性とその可能性を再強調します。
AIの重要性
- 効率と生産性の向上: AIはタスクの自動化と効率化に貢献し、作業の生産性を向上させます。これにより、人間はより創造的な仕事に時間を費やすことができます。
- 新たなビジネスモデル: AIは新たなビジネスモデルの創出を可能にし、競争力を高めます。データ駆動型の意思決定やカスタマイズされたサービスは、顧客に価値を提供します。
- 医療と健康ケア: AIは医療診断や治療計画の向上に寄与し、病気の早期発見や効果的な治療をサポートします。これにより、健康ケアの品質が向上します。
- 教育とアクセス: AIを活用した教育は個別に合わせた学習体験を提供し、教育のアクセスを向上させます。地理的な制約を克服し、学習者に世界中の知識にアクセスする機会を提供します。
AIの可能性
- 自己学習の進化: AIは自己学習能力を高め、新たな環境やタスクに適応できるようになるでしょう。これにより、AIはさまざまな分野でさらなる進歩を遂げます。
- 人間の知能に匹敵するAGI: AGIの実現に向けた研究が進行中であり、将来的には人間の知能を模倣できるAIが誕生するかもしれません。これにより、複雑な問題の解決やクリエイティビティの領域でAIが活躍するでしょう。
- 社会への貢献: AIはエネルギー効率の向上や環境保護、サステナビリティに貢献します。交通制御、エネルギー管理、環境モニタリングなどでAIの利用が増えます。
- 多様な分野への応用: AIは自動運転車、金融予測、自然言語処理、クリエイティブな業界など多くの分野に応用され、新たな可能性を切り拓きます。
AIの重要性と可能性は、私たちの生活と社会に深い影響を与えています。その一方で、AIの発展には倫理的な問題や課題も存在します。エシカルな使用と個人のプライバシー保護に対処しながら、AIの可能性を最大限に活かすために努力することが求められます。未来はAI技術によって大きく変革されるでしょうが、その変革を共に進化させ、社会全体に利益をもたらすために協力して取り組みましょう。
質問と回答
読者からのよくある質問への回答
10.1 AIとは何ですか?
AI(人工知能)は、コンピュータープログラムを使用して、人間の知識や能力を模倣する技術です。AIはデータを解析し、予測、意思決定、タスクの自動化などを行うことができます。具体的な例には、画像認識、音声認識、自然言語処理があります。
10.2 AIの歴史はどのようなものですか?
AIの歴史は1950年代に遡ります。初期のAI研究は専門家システムと論理推論に焦点を当てていました。その後、機械学習とディープラーニングの発展により、AIの性能が向上しました。AIのマイルストーンには、自動チェスプログラム、AlphaGoによる囲碁の世界チャンピオン破り、自動運転車の開発などが含まれます。
10.3 機械学習とディープラーニングの違いは何ですか?
機械学習は、データからパターンを学び、予測や意思決定を行う技術の一般的なカテゴリです。ディープラーニングは、多層のニューラルネットワークを使用して高度なタスクを実行する機械学習の一部です。ディープラーニングは特に大規模なデータセットと複雑なタスクに適しています。
10.4 AIの種類は何ですか?
AIにはさまざまな種類があります。強化学習は環境に対する行動を学ぶもので、自己学習能力を持ちます。教師あり学習はラベル付きデータを使用してモデルをトレーニングする方法です。教師なし学習はラベルなしデータからパターンを抽出します。自己教師あり学習は一部のデータからラベルを生成し、モデルをトレーニングします。
10.5 AIはどのような分野で応用されていますか?
AIはさまざまな分野で応用されています。例えば、自動運転車の開発、医療診断、金融予測、自然言語処理(翻訳、チャットボットなど)、クリエイティブな業界(音楽、映画、アート)、ロボティクス、エネルギー管理などがあります。AIはこれらの分野で効率性を向上させ、新たな可能性を切り拓いています。
10.6 AIの倫理的な課題は何ですか?
AIの倫理的な課題には、データプライバシー、人間の仕事への影響、偏ったデータ、バイアス、自己学習のコントロールなどが含まれます。AIの利用は倫理的なガイドラインや法的枠組みに従う必要があります。倫理と透明性に対する配慮が重要です。
10.7 AIを学ぶためのリソースはどこで見つけられますか?
AIを学ぶためのリソースは豊富にあります。オンラインコース(Coursera、edX、Udacityなど)、教材(無料のものから有料のものまで)、書籍、コミュニティ、フォーラムなどが利用可能です。選択肢は多岐にわたるため、自分の目標と学習スタイルに合ったリソースを選ぶことが重要です。
これらの質問と回答を通じて、AIに関する基本的な理解を深め、AI技術を活用し、その倫理的な側面に対処するための情報を得る手助けになれば幸いです。AIは常に進化し続けており、学習と情報収集が重要なスキルとなります。
Comments